Setup automatic speech recognition
For speech recognition you need a language model: one or more files trained with real speech samples. Parlatype supports language models made for CMU Sphinx and Mozilla DeepSpeech and ships a couple of language model configurations.
A language model configuration contains meta data describing the language model: A name that you can change, the language it was made for, speech recognition engine, publisher, license etc. It has a (third party) link, where you can download the files. Part of the configuration is the base folder, where you have saved the model. Additionally it contains various parameters for the plugin which are not shown.
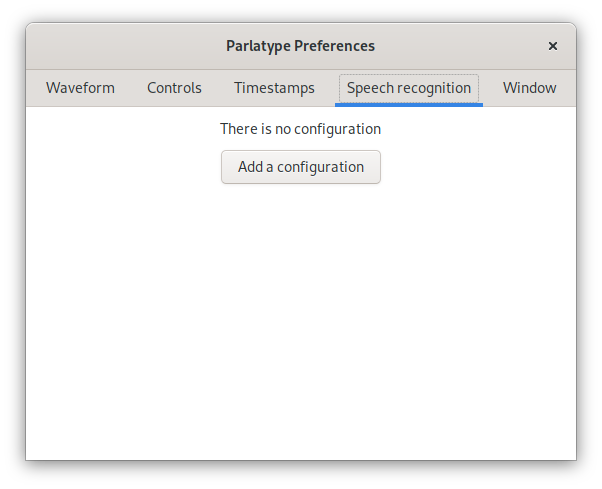
Open the Preferences Dialog and click on the Speech Recognition tab. Initially there are no configurations available, click on the Add a configuration button.
If your installation has CMU Sphinx or Mozilla DeepSpeech enabled, you will
see configurations with a  symbol.
Otherwise you will see only configurations with a
symbol.
Otherwise you will see only configurations with a  symbol.
symbol.
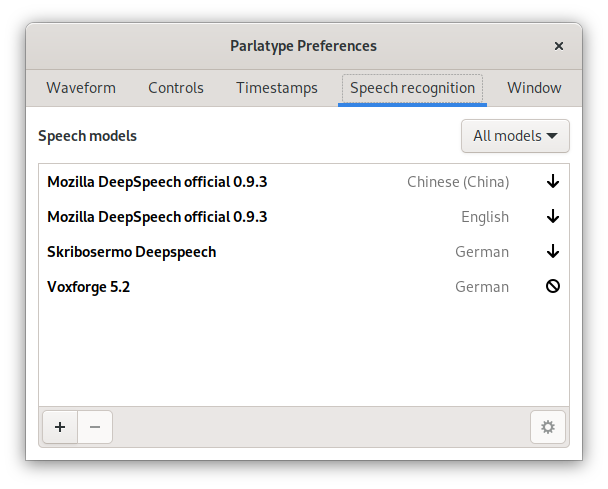
Select a configuration and click on the
 button.
There is a short description of the model and where you can download it.
After downloading, you have to set the folder where your download resides.
You can also change the Display name.
button.
There is a short description of the model and where you can download it.
After downloading, you have to set the folder where your download resides.
You can also change the Display name.
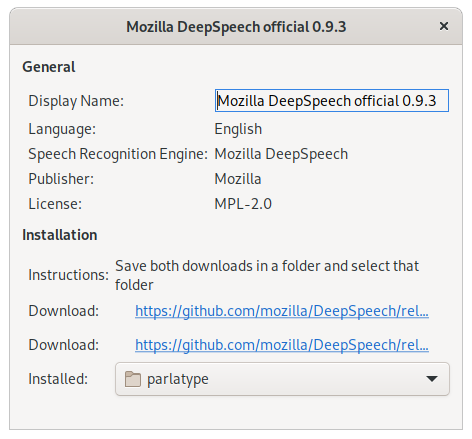
An installed model has no symbol next to it. Double click on the model and
it will be selected for speech recognition, a  symbol
appears.
symbol
appears.
Shipped configurations might get obsolete over time. Therefore you can import a configuration with the + button. Configurations are text files with an .asr ending.
With the - button you can remove a configuration. This will never remove downloaded models, only the configuration file.